MaskRCNN - An Overview¶
MaskRCNN is rather a complex model and the best way to understand it is through implementation. In subsequent tutorials I am going to step through implementing all aspects this model. Here, I will provide a brief overview of the model so that so you can see in one place how they all the components come together.
Fast(er) RCNN¶
The model presented in the MaskRCNN paper is actually a fairly simple extension of the FasterRCNN object detection model to turn it into an instance segmentation model. The complexity is due to the FasterRCNN model. MaskRCNN belongs to a family models that deal with the problem of identifying individual instances of objects by using two stage approach. In the first stage we identify regions of interest within the image, known as region proposals. In the second stage we refine these regions of interest to output predicted bounding boxes (and possibly segmentation masks). for objects in the image. We also predict labels for the class of object within each bounding box.
The model consists of the following components
- Backbone network
- Region proposal network (RPN) which is stage 1
- Detection network which is stage 2
Backbone network¶
Both of the stages share a common backbone network. The backbone network can be any architecture. For example in the Faster RCNN paper one of the architectures they tried was VGG-16. ResNet models are also popular backbones. The backbone architecture acts on the entire image and outputs a feature map which serves as the input to the region proposal network and the detection network.
Region proposal network¶
This takes as input the feature maps from the backbone network and has a pair of outputs:
- A fixed number of bounding boxes for potential regions of interest (RoIs) across the image.
- A probability for each bounding box of whether it contains an object,
To understand how this the model works, first we need to introduce the idea of anchor boxes. We can think of these as initial bounding boxes for locations all across the image. The model has to refine these to provide bounding boxes around potential RoIs across the image. Typically we have anchor boxes with different scales and aspect ratios to enable the model to learn to predict bounding boxes effectively for objects of different sizes and shapes.
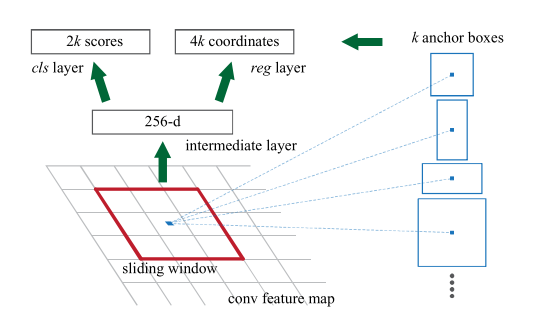
Object detection network¶
The input for this stage are feature maps from the backbone and RoIs from the RPN. The goal of this stage is to classify the object in the RoI and refine the bounding boxes from the RPN, leading to the following two outputs:
- Refined bounding boxes
- Softmax probability for the class of the object within the bounding box
The RoIs are used to crop regions from the feature maps which are these passed through a network to provide the outputs. Since the cropped regions will have different sizes, the first step involves passing them through a pooling layer which uses a pooling method called RoIPooling which results in fixed size outputs.
RoIPooling¶
The crops are divided into a fixed number of blocks (with variable numbers of pixels for each RoI) and the pixels within each block are aggregated for example by max-pooling. This results in a fixed size feature map for each crop.
